
Важные новости


Важные новости
Общество 2026.06.22

Червоний Хрест і тінь Вороніна
Общество 2026.06.16

Хімічний зашморг Кремля: як олігарх Фірташ тримає в заручниках український агросектор та суди
Программа AI AlphaGo Zero за несколько часов самообучения стала лучшей в игре в шахматы, Го и японские шахматы

Программе искусственного интеллекта AlphaGo Zero, разработанной подразделением DeepMind компании Google, потребовалось всего четыре часа времени игры самой с собой для того, чтобы достичь уровня игры, превосходящего уровень игры в шахматы любого человека или другой компьютерной программы. В матче из 100 игр программа AlphaGo Zero одержала победу со счетом 28:0 над программой Stockfish, которая уже достаточно давно является мировым чемпионом по шахматам среди компьютерных программ, сообщает dailytechinfo.org.
Процесс обучения программы AlphaGo Zero всегда начинается с нуля, в программу вводятся только базовые правила самой игры. После этого, программа начинает играть сама с собой, делая с начала самые случайные ходы. Через непродолжительное время программа начинает накапливать опыт и уровень ее игры заметно повышается. За 24 часа такого самообучения программа AlphaGo Zero приобрела "сверхчеловеческий" уровень игры в шахматы, Го и Сеги (японские шахматы), одержав каждый раз убедительную победу над другой программой, имеющей звание чемпиона мира среди компьютерных программ в данном виде.
Такая скорость и эффективность процесса самообучения стали результатом длительного подбора параметров работы и настроек искусственной нейронной сети, которая лежит в основе системы искусственного интеллекта. Подбор же некоторых других параметров возложен на саму программу и она выполняет эту задачу, используя метод оптимизации Байса. Единственным "искусственным" моментом в процессе самообучения является "шум" в виде набора случайных данных, который является тем, что толкает программу сделать первый ход и запустить процесс самообучения.
Как уже упоминалось выше, перед началом процесса самообучения в программу вводятся все правила и базовые принципы игры. Интересным является то, что эти правила и допустимые действия кодируются в виде плоских (двухмерных) и трехмерных векторов.
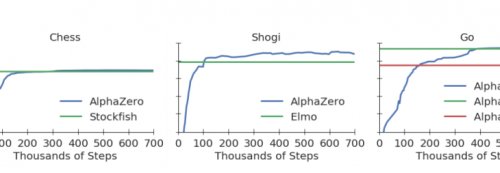
Универсальность нового метода самообучения подтверждается тем, что при обучении программы AlphaGo Zero игре в шахматы, Го и Сеги использовался один и тот же набор стартовых параметров, настроек алгоритмов и архитектура нейронной сети. Каждый отдельный экземпляр программы AlphaGo Zero обучался какому-либо одному виду игры, и обычно процесс обучения укладывался в 700 тысяч ходов, сделанных программой. В данном процессе были задействованы мощности 5000 специализированных процессоров TPU первого поколения и 64 TPU-процессоров второго поколения.
Программа AlphaGo Zero выиграла в шахматы у программы Stockfish после 4 часов самообучения, в течении которых она сделала 300 тысяч ходов. В Сеги программа AlphaGo Zero одержала победу над программой Elmo после 2 часов и 110 тысяч сделанных ходов. А в Го программа AlphaGo Zero одержала победу над программой AlphaGo Lee после восьми часов и 165 тысяч ходов самообучения.
 Происшествия «Правоохоронні органи назвали причину смерті командира 154 ОМБр Володимира Кононнікова»
Происшествия «Правоохоронні органи назвали причину смерті командира 154 ОМБр Володимира Кононнікова»  Экономика «В Україні через спеку обмежать електропостачання для бізнесу та населення»
Экономика «В Україні через спеку обмежать електропостачання для бізнесу та населення»  Политика «До Верховної Ради внесли законопроєкт про Український національний пантеон»
Политика «До Верховної Ради внесли законопроєкт про Український національний пантеон»  Мир «З березня 2027 року Сербія відновить строкову військову службу, – Вучич»
Мир «З березня 2027 року Сербія відновить строкову військову службу, – Вучич»  Мир «Аномальна спека: У Франції загинули понад 1000 людей»
Мир «Аномальна спека: У Франції загинули понад 1000 людей»  Киев «У Києві встановлять пам'ятник гетьманові Івану Мазепі»
Киев «У Києві встановлять пам'ятник гетьманові Івану Мазепі»